この記事では、いかにCHSH不等式が直感的かつ成立して当たり前の不等式であるかを解説し、十分に愛着を持っていただいた後、それが成立しない実験の例をお伝えする構成でお届けします。
CHSH不等式とは何か
我々は普段、
局所性: 十分に隔たりのある2つの時空点における事象は互いに影響しない。
実在性: 測定前から物理量は値を持っている。
という世界観を抱きがちです。この2つを兼ね備えた理論を局所実在論と呼びます。もし実験結果が局所実在論で説明できるなら、その結果は何かしらの数学的条件を満たすはずです。その代表例の一つがベルの不等式であり、ここで扱うCHSH不等式です。
CHSH不等式は、4つの物理量 \({A, B, C, D}\) の相関に関する次の不等式です。
ここで \(\langle AB\rangle\) などは(確率分布に関する)期待値相関を表す記号です。
見た目は単純ですが、なぜこの形なのかは最初は分かりにくいです。
もし単に相関の強さの上限を言いたいだけなら、例えば
のような形を予想したくなります。ところが実際には絶対値はつかず、最後の項だけにマイナスがついています。
従って、単に相関の強さに上限があるといった分かりやすいことを示しているわけではなさそうです。
CHSH不等式導出の前提条件
4つの物理量を用意する
まず、4種類の物理量 \({A, B, C, D}\) を考えます。各量は1回の測定ごとに \(+1\) または \(-1\) のどちらかを返すとします。
\(n\) 回の試行を行うと、4列のデータ表を作ることができます。対応するデータ列を \({\mathbf{A}, \mathbf{B}, \mathbf{C}, \mathbf{D}}\) と書くことにします。
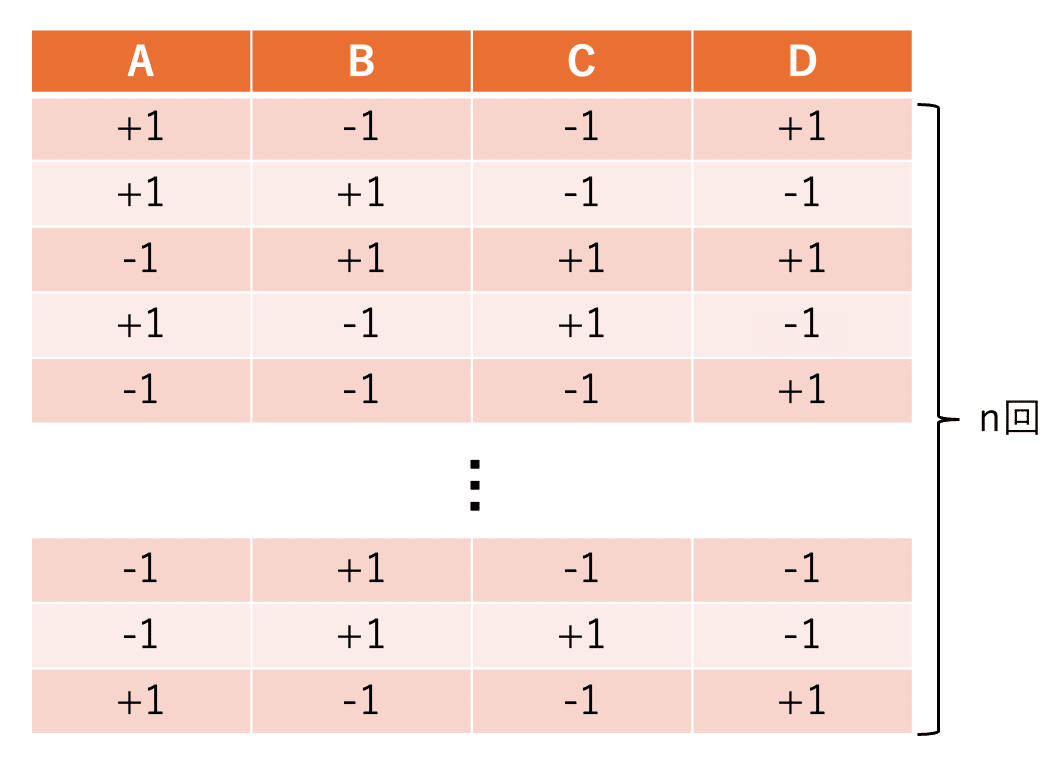
データの類似度を測るハミング距離を導入する
上で用意した2値データは、物理量ごとに長さ \(n\) の列になっています。二値列 \(\mathbf{u}, \mathbf{v}\) に対して、その列がどれくらい似ているかを測る自然な量がハミング距離です。定義は
です。これは、対応する成分が異なる割合を表しています。
ここで各成分は \(\pm 1\) のどちらかなので、\(u_i \neq v_i\) であることと \(u_iv_i = -1\) であることは同じです。したがって、標本相関
を使うと、
と書けます。ここで大事なのは、距離と相関がすでに1対1に結びついていることです。
具体例を見ます。
このとき異なるのは4番目だけなので、
です。全て等しければ距離は \(0\)、全て異なれば距離は \(1\) になります。
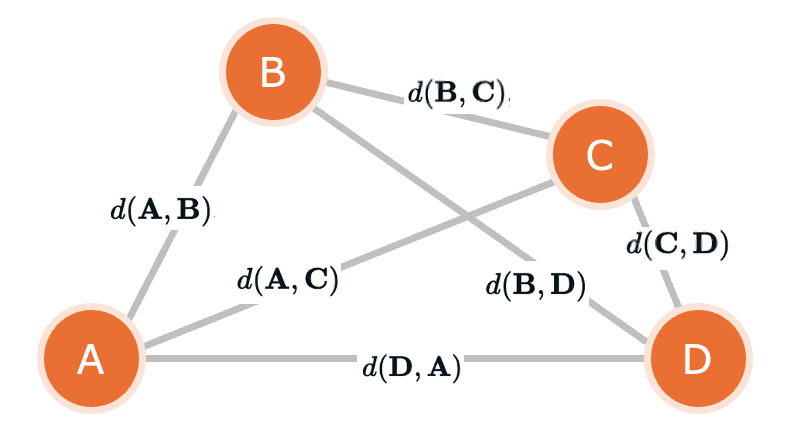
ハミング距離はふつうの距離と同じく、非負性、対称性、三角不等式を満たします。したがって、今回のデータテーブルの4列 \({\mathbf{A}, \mathbf{B}, \mathbf{C}, \mathbf{D}}\) の間には
という距離が定まります。
これらのデータ列とその間の距離を可視化すると以下のようになります。
CHSH 不等式の導出
CHSH不等式
が(期待値相関の形で書かれた)CHSH不等式です。以下ではまず、有限回 \(n\) の試行から作った標本相関 \(\langle \cdot \rangle_n\) について同じ形の不等式が成り立つことを距離の議論で示し、最後に \(n\to\infty\) でこの形に戻します。これは下限と上限の2つの不等式を1行にまとめたものです。対象に見えますが、それぞれの不等号で導出過程が異なります。
距離の基本的な性質
まず、\(\mathbf{A} \to \mathbf{B} \to \mathbf{C} \to \mathbf{D}\) という道順を考えます。
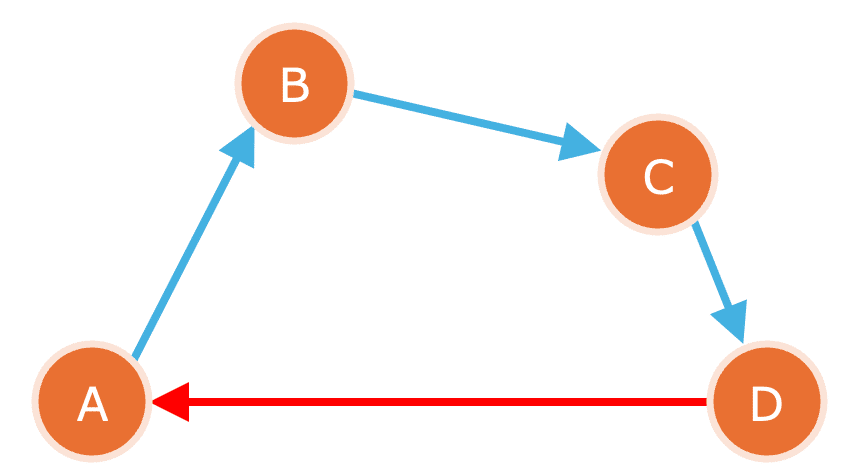
三角不等式を順に使うと、
が従います。
これは図から明らかなように「寄り道すると移動距離が伸びる」という当たり前の性質を反映しています。
二値データ固有の性質
二値データでは、任意の3列 \({\mathbf{X}, \mathbf{Y}, \mathbf{Z}}\) に対して
が成り立ちます。なぜなら、各試行で取りうる値は2種類しかないので、3つの値が互いに全部違うということは起こらないからです。したがって、1回の試行ごとに数えると、不一致の総数は高々2つまでです。
この性質を \({\mathbf{A}, \mathbf{B}, \mathbf{C}}\) に適用すると、
です。一方、三角不等式から
なので、2つを合わせて
が得られます。
CHSH不等式 = データの距離の性質
2つの不等式を合わせると、
となります。
これに相関と距離の関係式
を代入すると、
という不等式が得られます。
各項は有界確率変数の標本平均なので、大数の法則により
が成り立ちます。
よって不等式全体で \(n\to\infty\) の極限を取ると、CHSH不等式
が得られます。
導出過程から明らかなように、これはデータ間の距離の不等式
を相関の不等式に書き換えただけであるため、CHSH不等式はデータ間の距離が持つ当たり前の性質を表していると言えます。
どうやって実験するのか
4つの物理量から2つ選んで作れる相関関数は全部で6つありますが、CHSH不等式に出てくる相関は
の4つだけです。\({\langle AC\rangle,\langle BD\rangle}\) はこの不等式を評価するためには不要であり、「同時に測定しなくてよいペア」になっています。その結果、\({A,C}\) と \({B,D}\) の2グループに分けられ、CHSHに出てくる各相関は必ずグループ間の相関として現れます。
ここで以後は、2グループに合わせて記号を整理し、片側を \({A,A'}\)、もう片側を \({B,B'}\) と書くことにします(つまり \(C\to A'\)、\(D\to B'\) と書き換えます)。
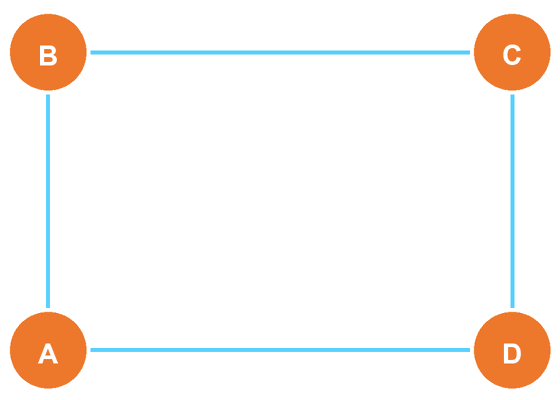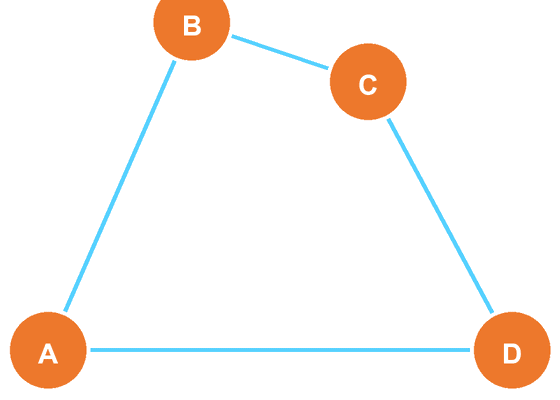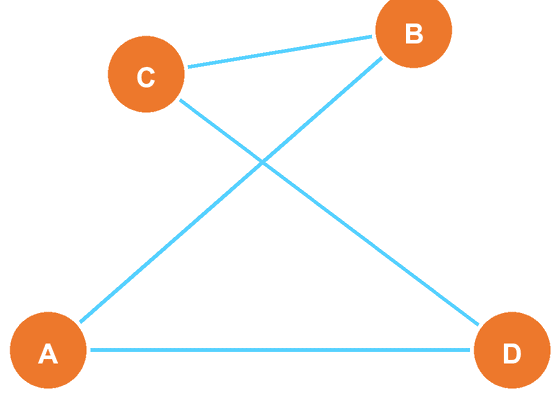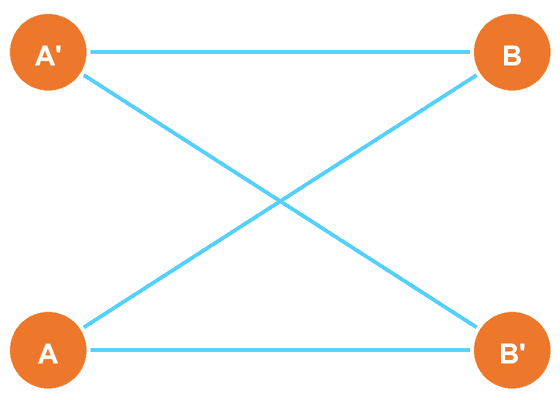
(スマホだとGIFが動かないかもです)
このとき、測るべき相関は「片側から1つ、もう片側から1つ」を選んだ4通り
だけです。
ここで、毎回4つのペア
のうちどれか1つをランダムに選んで測定するとし、ペアに現れなかったものは測定しないこととします。
これを4列の測定データテーブルを使って捉え直すと、各行ごとに \({A,A'}\) と \({B,B'}\) から1つずつランダムに選び、そのペアについてだけ測定したことにし、それ以外は破棄することに相当します。
データテーブルは無限に長く、測定ペアの取り方はテーブルと独立にランダムに行うため、測定したデータに絞って平均を取り直しても大数の法則は変わらず成立し、元の \(\langle AB\rangle\) と一致するはずです。
したがって、2グループに分けて「毎回ランダムに4通りのペアのうち1つだけ測る」という実験手順で相関を推定しても、結局は同じCHSH不等式へたどり着きます。
以上が成り立つため、実際の実験では、4通りのペアのうち1つだけを毎回ランダムに選んで、ペアの物理量だけを測定します。
実はこうすることで、量子論か局所実在論かにかかわらず、同じフォーマットで実験を行うことができるようになります。
局所実在論であることがどこに効いていたか
ベルの不等式(CHSH不等式)の文脈で気にされている前提は、局所性・実在性・独立性(測定設定の自由)の3つです。これらがどこで効いているかをCHSHの実験手順に即して整理するために、1回の試行を
選択フェーズ:測定する物理量のペアを選ぶ。
測定フェーズ:選んだ設定で測定し、結果を得る。
の2つに分けて見ます。
この時、局所性と独立性は「選択フェーズ」に関係し、実在性は「測定フェーズ」に関係しています。
選択フェーズ
先ほどの設定では、4ペア \({(A,B),(A,B'),(A',B),(A',B')}\) のうちどれを測るかは、そのテーブル(やそれを決める隠れ変数)とは独立にランダムに選択する、という仮定のもとに、測定するペアを選ぶものとしています。
この仮定が独立性を反映しています。
次に局所性について見ていきます。
\(A\) 側の物理量の選択が瞬時に \(B\) 側の測定結果に影響を与えるとしたら、その影響を介して相対論的因果律に違反した超光速通信が可能になってしまいます。
そうのような相対論的因果律に反しないこと、すなわち、物理量の選択が瞬時には他方の物理量に影響しないことを局所性と呼んでいます。
先ほどの設定だとテーブルの値はあらかじめ決めていましたし、選択の前後でそれが変化するようなこともない設定だったため、自動的にこの局所性が満たされる設定となっていました。
測定フェーズ
先ほどの設定では、先にテーブルの値が固定されており、測定はその値をただ確認するだけというモデルとなっています。
これは測定するかしないかに関わらず値が定まっているという実在性の仮定そのものです。
以上から、4列のデータテーブルからランダムに測定するモデルは、独立性・局所性・実在性を暗黙のうちに満たされていたことが分かりました。
どの仮定もとても当たり前に思えますね。
そろそろベルの不等式が肌に馴染んできたと思います。
最後に、ベルの不等式を破るアスペの実験とそれを正確に説明する量子論を紹介して終わろうと思います。
ベルの不等式を破ってみる
1980年代のアスペの実験では、左右に離れた2つの測定器で偏光を測り、左では \({A,A'}\)、右では \({B,B'}\) のどちらを測るかを毎回切り替えながら相関を調べました。各回で実際に得られるのは \({(A,B),(A,B'),(A',B),(A',B')}\) のうち1つの組のデータだけですが、これをたくさん集めて4つの相関を作ると、実験ではCHSH不等式が破れます。
ここで大事なのは、前半の導出が間違っていたのではない、ということです。あの導出では、各試行に対して \({A,A',B,B'}\) の4つの値が最初から並んだ4列テーブルを考えていました。だから4本のデータ列を同じ空間の点として扱うことができ、ハミング距離を入れて三角不等式を使えました。
しかし量子論では、同じ側の \(A\) と \(A'\)、あるいは \(B\) と \(B'\) は一般に非可換です。そのため、1回の試行に対してそれらの値を同時に並べた4列テーブルそのものが作れません。すると \({\mathbf{A},\mathbf{A}',\mathbf{B},\mathbf{B}'}\) を同じデータ空間の点として置くこともできず、前半で使った距離の議論は出発点から使えなくなります。
したがって、量子論ではCHSH不等式が破れても不思議ではありません。ベルの不等式の破れは、量子論が「4列テーブルで記述できる世界」ではないこと、つまり非可換性のためにその距離不等式の土台自体が成り立たないことを示しているのです。
最後に
ここまでで、CHSH不等式がデータ間の距離の性質から出てくること、そして量子論ではその前提がどこで崩れるのかを見ました。ベルの不等式の面白さは、抽象的な哲学ではなく、測定データの作り方そのものに現れている点にあります。